
本記事3行要約:
● ICML2022で過去最多の1,233件もの論文が発表された
● 日本人研究者で最多累積採択数は10年間で44件
● 論文出現キーワードではReinforcement Learning=強化学習が圧倒的多数
以前のトップカンファレンス定点観測シリーズ記事で、CVPRやNeurIPSの概観を書きました。
vol.4となる今回は、7月末に計算機科学分野きっての会議の一つであるICMLが開催されましたので、他カンファレンス同様にまとめてみました。
ICMLは、文字通り機械学習分野の最高峰国際会議ですが、NeurIPSやICLRと並んで最も高いインパクトファクターを記録しているカンファレンスです。第1回は、1980年に米国ペンシルベニア州ピッツバーグで開催されました。それ以来ずっとこの分野をリードしてきたと言えます。
統計情報はあまり残っていなかったため、収集可能な情報のみで俯瞰してみました。
■ICML2022総括
ICML2022は、7/17-23の7日間にわたり米国メリーランド州ボルチモアで開催され、ICML史上最高数の論文が発表されました。昨年までの2年間、COVID-19の影響でオンライン開催のみだったため久々のオンサイト開催でした。
まずはいつも通り、論文数・採択率などの推移を見ていきます。Proceedings of Machine Learning Researchに掲載されている2013年からの情報を表1-1・1-2と図1にまとめました。
| Year | Conference | #papers | #submissions | acceptance rate | Venue |
|---|---|---|---|---|---|
| 2013 | ICML | 283 | – | Atlanta,US | |
| 2014 | ICML | 310 | – | Beijing,CN | |
| 2015 | ICML | 270 | 1,037 | 26.04% | Lille,FR |
| 2016 | ICML | 322 | 1,342 | 23.99% | New York,US |
| 2017 | ICML | 434 | 1,676 | 25.89% | Sydney,AU |
| 2018 | ICML | 621 | 2,473 | 25.11% | Stockholm,SE |
| 2019 | ICML | 773 | 3,424 | 22.58% | Long Beach,US |
| 2020 | ICML | 1,084 | 4,990 | 21.72% | Vienna,AT |
| 2021 | ICML | 1,183 | 5,513 | 21.46% | Honolulu,US |
| 2022 | ICML | 1,233 | 5,630 | 21.90% | Baltimore,US |
表1-1 ICML論文投稿数および採択率
| Year | JPN paper | JPN paper rate | ALL authors | JPN authors | JPN authors rate | averate aturhos |
|---|---|---|---|---|---|---|
| 2013 | 5 | 1.77% | 875 | 14 | 1.60% | 3.09 |
| 2014 | 14 | 4.52% | 963 | 25 | 2.60% | 3.11 |
| 2015 | 8 | 2.96% | 864 | 16 | 1.85% | 3.20 |
| 2016 | 10 | 3.11% | 1,153 | 26 | 2.25% | 3.58 |
| 2017 | 15 | 3.46% | 1,588 | 34 | 2.14% | 3.66 |
| 2018 | 21 | 3.38% | 2,316 | 40 | 1.73% | 3.73 |
| 2019 | 25 | 3.23% | 2,893 | 41 | 1.42% | 3.74 |
| 2020 | 44 | 4.06% | 4,226 | 76 | 1.80% | 3.90 |
| 2021 | 48 | 4.06% | 4,844 | 74 | 1.53% | 4.09 |
| 2022 | 37 | 3.00% | 5,373 | 78 | 1.45% | 4.36 |
表1-2 日本人研究者が関連する論文とその著者数・平均共著人数
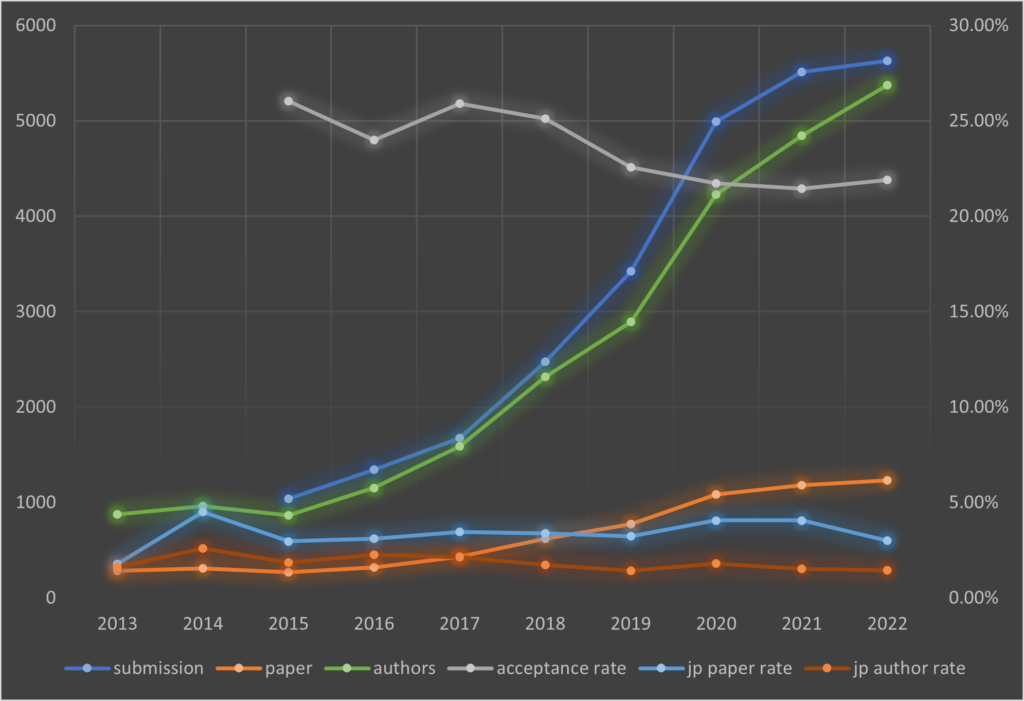
今年は、5,630件の論文が投稿され、その内1,233件が採択されました。採択率は21.9%です。
投稿数を2015年と比較すると、1,037件から5.4倍にも増加しております。採択率はここ数年変わらず21%台で横ばいとなっております。参考までに、他トップカンファレンスの採択率は、NeurIPS 20-25%程度、CVPR 23-25%程度です。これらを見てもICMLがいかに難易度の高いものかご理解いただけるかと思います。
なお、論文投稿数は昨年比で微増の1%強にとどまっており、AIブームも理論面では一旦落ち着いてきたのかもしれません。
■日本人研究者の活躍
CVPR2022に続き、日本人研究者がどれだけ活躍されているのかということもまとめてみました(図2)。日本人らしい名前を判定するプログラムを作成し、個人別で論文数を抜き出しております。
注)判定に引っかからず抜けてしまっている著者の方がいらっしゃれば申し訳ありません。また所属機関が日本にない場合や、日本の機関であっても海外のお名前を持たれていると判定された方は含まれておりません。
結果として、78件の日本人研究者が見つかり、全体の著者数5,373名に対しておよそ1.45%だったことが分かります。論文タイトルで見てみると、日本人が含まれるもの37件で、採択1,233件のうち3.00%という結果でした。
1論文あたりの平均著者数は、CVPRなど他難関カンファレンスでも言えることですが、やはり増加の一途をたどっております。ICML2022では4.36名(過去最多人数)ということで、機械学習の理論面での研究においてもチーム競争力が試されるようになってきているようです。
視点を変えて、日本人名が確認できた78件を解析すると、1人で複数件採択されている研究者が9人もおりました(図2参照)。
日本人研究者別採択数
| 著者 | 採択数 |
|---|---|
| Kenji Kawaguchi |
3
|
| Masashi Sugiyama |
3
|
| Ikuro Sato |
2
|
| Kazuki Irie |
2
|
| Masatoshi Uehara |
2
|
| Masayuki Karasuyama |
2
|
| Rei Kawakami |
2
|
| Shinichi Nakajima |
2
|
| Shion Takeno |
2
|
| Gaku Morio |
1
|
| Haruki Sato |
1
|
| Hidetaka Kamigaito |
1
|
| Hiroaki Ozaki |
1
|
| Hiroki Ishikura |
1
|
| Hisashi Kashima |
1
|
| Ichiro Takeuchi |
1
|
| Isao Ishikawa |
1
|
| Kaito Ariu |
1
|
| Kanji Uchino |
1
|
| Katsuhiko Hayashi |
1
|
| Katsuki Fujisawa |
1
|
| Kazuki Shitara |
1
|
| Kazushi Kawamura |
1
|
| Kazutoshi Hirose |
1
|
| Keiichiro Yamamura |
1
|
| Kenshi Abe |
1
|
| Kento Nozawa |
1
|
| Koji Maruhashi |
1
|
| Kota Ando |
1
|
| Makoto Yamada |
1
|
| Masahiro Ikeda |
1
|
| Masahito Ueda |
1
|
| Masato Motomura |
1
|
| Masayuki Tanaka |
1
|
| Nakamasa Inoue |
1
|
| Naoki Murata |
1
|
| Nariaki Tateiwa |
1
|
| Nobuo Nukaga |
1
|
| Nozomi Hata |
1
|
| Ryoma Sato |
1
|
| Satoshi Kataoka |
1
|
| Shingo Yashima |
1
|
| Shinji Ito |
1
|
| Shinji Watanabe |
1
|
| Sho Sonoda |
1
|
| Sho Takemori |
1
|
| Shota Horiguchi |
1
|
| Shusuke Takahashi |
1
|
| Takaaki Shiratori |
1
|
| Takashi Mori |
1
|
| Takashi Shibuya |
1
|
| Tatsunori Hashimoto |
1
|
| Terufumi Morishita |
1
|
| Tomoko Matsui |
1
|
| Tomoyuki Tamura |
1
|
| Toru Mitsutake |
1
|
| Toshimitsu Uesaka |
1
|
| Toshiyuki Kumakura |
1
|
| Urano Daisuke |
1
|
| Yamada Ryota |
1
|
| Yasutaka Furukawa |
1
|
| Yasuyuki Okoshi |
1
|
| Yoshihiro Nagano |
1
|
| Yu Inatsu |
1
|
| Yuka Hashimoto |
1
|
| Yuki Mitsufuji |
1
|
| Yuta Saito |
1
|
図2 ICML2022日本人研究者別採択数
もう一歩踏み込んで、ICML2013からの累積採択数(日本人研究者)も確認してみましょう。
3本以上の論文を出された研究者でフィルタリングして集計いたしました(図3)。
トップは、なんと44件という圧倒的な数の論文を出した理研API/東京大学 杉山将先生でした。改めてその数量に圧倒されました。次いで、理研AIP/名古屋工業大学 竹内一郎先生、理研API/東京大学 鈴木大慈先生、両名が10件で同着でした。
累積採択数
| 著者 | 採択数 |
|---|---|
| Masashi Sugiyama |
44
|
| Ichiro Takeuchi |
10
|
| Taiji Suzuki |
10
|
| Masatoshi Uehara |
6
|
| Junya Honda |
5
|
| Kenji Kawaguchi |
5
|
| Masayuki Karasuyama |
5
|
| Ryohei Fujimaki |
5
|
| Tatsunori Hashimoto |
5
|
| Hiroshi Nakagawa |
4
|
| Kenji Fukumizu |
4
|
| Makoto Yamada |
4
|
| Michihiro Yasunaga |
4
|
| Shion Takeno |
4
|
| Shiori Sagawa |
4
|
| Akihiro Yabe |
3
|
| Hiroshi Kajino |
3
|
| Hiroyuki Kasai |
3
|
| Hisashi Kashima |
3
|
| Ikuro Sato |
3
|
| Junpei Komiyama |
3
|
| Kazuki Irie |
3
|
| Kohei Hayashi |
3
|
| Kohei Ogawa |
3
|
| Naonori Kakimura |
3
|
| Shinichi Nakajima |
3
|
| Shinji Ito |
3
|
| Takanori Maehara |
3
|
| Yuta Saito |
3
|
| Yuu Jinnai |
3
|
図3 ICML2013からの累積採択数(日本人研究者)
■トレンドキーワードの推移
ICMLにおいても、論文出現キーワードの推移を見てみました。タイトルのみを対象とし、タスクレベルと手法レベルでキーワードを抜き出し、それぞれの出現頻度を観測しました(表2-1.2.3.4)。
2013~2015年はL0/1系の最適化などに代表されるスパース系のトピックスが多かったのですが、2016年にReinforcement Learning(=強化学習)が躍り出て、2017年以降は一気に多様性が消えて他のトピックスを食った様子が見て分かります。
| 2022 | |
|---|---|
| reinforcement learning | 12.98% |
| federated learning | 5.19% |
| adversarial | 3.57% |
| contrastive learning | 3.08% |
| representation learning | 2.76% |
| priva | 2.27% |
| sparse | 2.11% |
| meta learning | 1.78% |
| neural network | 1.78% |
| active learning | 1.62% |
| online | 1.54% |
| transformer | 1.54% |
| off policy | 1.46% |
| attention | 1.46% |
| fair | 1.38% |
| deep learning | 1.38% |
| domain adaptation | 1.30% |
| continual learning | 1.14% |
| self supervis | 1.14% |
| pre training | 1.14% |
| supervised learning | 0.89% |
| convex optimization | 0.89% |
| bandit | 0.81% |
| diffusion | 0.81% |
| gaussian process | 0.81% |
| disentangl | 0.73% |
| imitation learning | 0.65% |
| adversarial robust | 0.65% |
| memory | 0.65% |
| efficient learning | 0.57% |
| transfer learning | 0.57% |
| zero shot | 0.57% |
| machine learning | 0.57% |
| boosting | 0.57% |
表2-1 論文出現キーワード推移(最新2022年)
| 2019 | 2020 | 2021 | |||
|---|---|---|---|---|---|
| reinforcement learning | 11.64% | reinforcement learning | 11.44% | reinforcement learning | 16.06% |
| adversarial | 5.95% | adversarial | 4.70% | adversarial | 3.55% |
| deep learning | 1.94% | off policy | 2.40% | meta learning | 2.37% |
| fair | 1.81% | representation learning | 2.03% | federated learning | 2.20% |
| off policy | 1.81% | priva | 1.75% | representation learning | 2.20% |
| representation learning | 1.55% | online | 1.75% | priva | 2.03% |
| priva | 1.42% | fair | 1.66% | sparse | 1.94% |
| online | 1.42% | meta learning | 1.66% | attention | 1.86% |
| sparse | 1.29% | domain adaptation | 1.66% | off policy | 1.69% |
| stochastic gradient | 1.29% | sparse | 1.57% | contrastive learning | 1.69% |
| meta learning | 1.29% | gaussian process | 1.29% | online | 1.52% |
| neural network | 1.29% | neural network | 1.20% | gaussian process | 1.52% |
| domain adaptation | 1.29% | generative model | 1.01% | fair | 1.27% |
| convex optimization | 1.29% | machine learning | 1.01% | deep learning | 1.01% |
| active learning | 1.03% | stochastic gradient | 0.92% | few shot | 0.93% |
| disentangl | 1.03% | convex optimization | 0.92% | convex optimization | 0.93% |
| generative model | 1.03% | federated learning | 0.92% | transformer | 0.85% |
| bandit | 0.91% | self supervis | 0.92% | neural network | 0.85% |
| attention | 0.91% | deep learning | 0.83% | domain adaptation | 0.85% |
| memory | 0.78% | memory | 0.83% | continual learning | 0.85% |
| federated learning | 0.78% | attention | 0.74% | bandit | 0.76% |
| gaussian process | 0.78% | adversarial robust | 0.74% | disentangl | 0.76% |
| online learning | 0.78% | imitation learning | 0.65% | memory | 0.68% |
| shot learning | 0.65% | online learning | 0.65% | neural networks | 0.68% |
| deep neural network | 0.65% | supervised learning | 0.65% | transfer learning | 0.59% |
| adversarial robust | 0.65% | boosting | 0.55% | self supervis | 0.59% |
| nonlinear | 0.65% | disentangl | 0.55% | active learning | 0.59% |
| machine learning | 0.52% | active learning | 0.55% | zero shot | 0.51% |
| neural networks | 0.52% | pre training | 0.55% | online learning | 0.51% |
| adversarial training | 0.52% | bandit | 0.55% | diffusion | 0.51% |
| expert | 0.52% | boost | 0.55% | metric learning | 0.51% |
| importance sampling | 0.52% | semi supervised | 0.55% | tangent kernel | 0.51% |
| pre training | 0.52% | mutual informat | 0.55% | ||
| imitation learning | 0.52% | transfer learning | 0.55% | ||
| transformer | 0.52% | transformer | 0.55% | ||
| structure learning | 0.52% | metric learning | 0.55% | ||
| zero shot | 0.52% | few shot | 0.55% | ||
表2-2 論文出現キーワード推移 (2019-2021年)
| 2016 | 2017 | 2018 | |||
|---|---|---|---|---|---|
| sparse | 4.97% | reinforcement learning | 9.22% | reinforcement learning | 12.88% |
| reinforcement learning | 4.97% | active learning | 3.00% | adversarial | 4.99% |
| memory | 2.17% | sparse | 3.00% | sparse | 2.74% |
| off policy | 1.86% | adversarial | 2.53% | deep learning | 2.09% |
| bandit | 1.55% | online | 2.30% | fair | 1.93% |
| supervised learning | 1.24% | gaussian process | 1.84% | priva | 1.61% |
| convex optimization | 1.24% | online learning | 1.61% | meta learning | 1.29% |
| gaussian process | 1.24% | stochastic gradient | 1.61% | gaussian process | 1.13% |
| priva | 1.24% | deep learning | 1.38% | convex optimization | 0.97% |
| nonparametric | 1.24% | priva | 1.15% | end to end | 0.97% |
| domain adaptation | 1.24% | end to end | 1.15% | stochastic gradient | 0.97% |
| deep learning | 0.93% | convex optimization | 1.15% | neural network | 0.97% |
| stochastic gradient | 0.93% | off policy | 0.92% | structure learning | 0.97% |
| nonlinear | 0.93% | imitation learning | 0.69% | transfer learning | 0.97% |
| online | 0.93% | zero shot | 0.69% | machine learning | 0.81% |
| precondition | 0.93% | machine learning | 0.69% | memory | 0.81% |
| attention | 0.93% | stochastic variance | 0.81% | ||
| semi supervised | 0.62% | adversarial learning | 0.64% | ||
| end to end | 0.62% | off policy | 0.64% | ||
| non linear | 0.62% | domain adaptation | 0.64% | ||
| stochastic variance | 0.62% | distributed learning | 0.64% | ||
| side informat | 0.62% | ||||
| tensor regression | 0.62% | ||||
| structure learning | 0.62% | ||||
| online learning | 0.62% | ||||
| risk minimization | 0.62% | ||||
| parameter estimation | 0.62% | ||||
| subspace clustering | 0.62% | ||||
| imitation learning | 0.62% | ||||
| structured prediction | 0.62% | ||||
| adversarial | 0.62% | ||||
| sparse model | 0.62% | ||||
| multi label classification | 0.62% | ||||
| multi label | 0.62% | ||||
| representation learning | 0.62% | ||||
| meta learning | 0.62% | ||||
| metric learning | 0.62% | ||||
表2-3 論文出現キーワード推移 (2016-2018年)
| 2013 | 2014 | 2015 | |||
|---|---|---|---|---|---|
| sparse | 7.07% | sparse | 2.90% | gaussian process | 5.19% |
| active learning | 3.89% | active learning | 2.58% | reinforcement learning | 2.22% |
| reinforcement learning | 3.53% | gaussian process | 2.26% | nonparametric | 1.48% |
| domain adaptation | 2.83% | online | 1.94% | online | 1.48% |
| boosting | 1.77% | bandit | 1.94% | metric learning | 1.48% |
| gaussian process | 1.41% | metric learning | 1.94% | risk minimization | 1.11% |
| semi supervised | 1.41% | reinforcement learning | 1.94% | online learning | 1.11% |
| adversarial | 1.41% | boosting | 1.61% | stochastic variational | 1.11% |
| topic model | 1.41% | stochastic gradient | 1.61% | neural network | 1.11% |
| nonparametric | 1.06% | topic model | 1.29% | priva | 1.11% |
| bandit | 1.06% | representation learning | 1.29% | stochastic gradient | 1.11% |
| non linear | 1.06% | non linear | 0.97% | convex optimization | 1.11% |
| convex optimization | 1.06% | nonparametric | 0.97% | memory | 0.74% |
| online | 1.06% | semi supervised | 0.97% | hamiltonian monte carlo | 0.74% |
| transfer learning | 1.06% | supervised learning | 0.97% | subsampling | 0.74% |
| spectral learning | 0.71% | multi label | 0.97% | distribution estimation | 0.74% |
| general frame | 0.71% | hamiltonian monte carlo | 0.97% | small variance | 0.74% |
| machine learning | 0.71% | memory | 0.97% | off policy | 0.74% |
| multiple kernel | 0.71% | online clustering | 0.65% | transfer learning | 0.74% |
| metric learning | 0.71% | online learning | 0.65% | bandit | 0.74% |
| multiple instance learning | 0.71% | hidden markov | 0.65% | unsupervised learning | 0.74% |
| instance learning | 0.71% | adversarial | 0.65% | topic model | 0.74% |
| hidden markov | 0.71% | norm minimization | 0.65% | boosting | 0.74% |
| unlabel | 0.71% | time markov | 0.65% | structured prediction | 0.74% |
| hilbert space | 0.71% | efficient kernel | 0.65% | task feature | 0.74% |
| incremental learning | 0.71% | function learning | 0.65% | representation learning | 0.74% |
| multi label | 0.71% | mutual informat | 0.65% | domain adaptation | 0.74% |
| task learning | 0.71% | covariance | 0.65% | subspace | 0.74% |
| online learning | 0.71% | task learning | 0.65% | sparse subspace | 0.74% |
| covariance | 0.71% | structured prediction | 0.65% | image generation | 0.74% |
| binary classification | 0.71% | nonparametric estimation | 0.65% | vector autoregressive | 0.74% |
| structured prediction | 0.71% | lifelong learning | 0.65% | active learning | 0.74% |
| dictionary learning | 0.71% | nonlinear | 0.65% | multi label | 0.74% |
| representation learning | 0.71% | diffusion | 0.65% | ||
| deep learning | 0.71% | stochastic variational | 0.65% | ||
表2-4 論文出現キーワード推移 (2013-2015年)
その次には、Adversarial(=敵対的学習)トピックスが2021年までずっと追いかける構図だったのですが、今年はFederated learning(=連合学習)が大きなトレンドになったことが分かります。
今年の上位から見てみると、強化学習・連合学習・敵対的学習・対象学習・表現学習・プライバシー*1・スパース・メタ学習までで8つのトレンドキーワードとなっています。応用系でよく見られるTransformerなども出現しているものの、理論系の本カンファレンスでは1.54%にとどまっています。
今回は出現率0.5%を超えるキーワードをリストアップしましたが、この9年間で採択論文数は283件→1,233件にまで増加しておりますので、同じ”0.5%”でも大きく意味合いが異なります。
2013年の下位キーワードは0.71%ですが、これは全論文のうち2件に出現したのみということです。一方で、2022年の下位キーワードの0.57%は7件に出現したということになります。
*1:差分プライバシーなど複数用語に分かれるため”priva”を含むもので統一。
論文の紹介やトレンドの中身の紹介は、様々な勉強会や研究者ブログなどで取り扱われておりますので、本記事では統計情報から全体を俯瞰して分析してみました。内容については適宜ご活用ください。
編集:ResearchPort事業部
■Contact
本記事に関する質問や、ご意見・ご要望などがございましたらResearchPortまでお問い合わせください。
https://research-p.com/contactform/
-
2026年4月23日
「ICLR 2026」ResearchPortトップカンファレンス定点観測 vol.21


