
本記事3行要約:
●CVPR2022で過去最多2,074件の論文が発表された
●日本人研究者の研究発表も多数
●トレンドキーワードでは[Transformer]が圧倒的多数
トップカンファレンス定点観測シリーズ vol.3、「CVPR」の第2弾です。
前回の記事で、コンピュータビジョン分野で最高峰の会議であるCVPR(IEEE/CVF Conference on Computer Vision and Pattern Recognition)における論文投稿数の増加とそれに伴う盛況感について書きました(参照:「CVPR」ResearchPortトップカンファレンス定点観測 vol.1)。
■CVPR2022総括
CVPR2022は、6/21-24の日程で開催され、CVPR史上最高数の論文が発表されました。以前まとめた、IEEEの論文集に統計が残っている1996年からの推移を更新いたしました(表1#submissionsの列を参照)。
前回記事で触れておりますが、2002年に記録がないのはSARSの影響で開催されなかったからと思われます。最近は、COVID19でもオンライン開催できるため、特に中止はなかったようです。図1にグラフでも表示しております。
| Year | Conference | #papers | #orals | #submissions | acceptance rate | oral acceptance rate | Venue |
|---|---|---|---|---|---|---|---|
| 1996 | CVPR | 137 | 73 | 551 | 39.93% | 13.25% | San Francisco,CA |
| 1997 | CVPR | 173 | 62 | 544 | 40.44% | 11.40% | San juan,Puerto Rico |
| 1998 | CVPR | 139 | 42 | 453 | 48.57% | 9.27% | Santa Barbara,CA |
| 1999 | CVPR | 192 | 73 | 503 | 43.74% | 14.51% | Fort Collins,CO |
| 2000 | CVPR | 220 | 66 | 466 | 47.21% | 14.16% | Hilton Head,SC |
| 2001 | CVPR | 273 | 78 | 920 | 29.67% | 8.48% | Kauai,HI |
| 2002 | CVPR | – | – | – | – | – | – |
| 2003 | CVPR | 209 | 60 | 905 | 23.09% | 6.63% | Madison,WI |
| 2004 | CVPR | 260 | 54 | 873 | 29.78% | 6.19% | Washington,DC |
| 2005 | CVPR | 326 | 75 | 1160 | 28.10% | 6.47% | San Diego,CA |
| 2006 | CVPR | 318 | 54 | 1131 | 28.12% | 4.77% | New York,NY |
| 2007 | CVPR | 353 | 60 | 1250 | 28.24% | 4.80% | Minneapolis,MN |
| 2008 | CVPR | 508 | 64 | 1593 | 31.89% | 4.02% | Anchorage,AK |
| 2009 | CVPR | 384 | 61 | 1464 | 26.23% | 4.17% | Miami,FL |
| 2010 | CVPR | 462 | 78 | 1724 | 26.80% | 4.52% | San Francisco,CA |
| 2011 | CVPR | 436 | 59 | 1677 | 26.00% | 3.52% | Colorado Springs,CO |
| 2012 | CVPR | 463 | 48 | 1933 | 23.95% | 2.48% | Providence |
| 2013 | CVPR | 471 | 60 | 1798 | 26.20% | 3.34% | Portland,OR |
| 2014 | CVPR | 540 | 104 | 1807 | 29.88% | 5.76% | Columbus,OH |
| 2015 | CVPR | 602 | 71 | 2123 | 28.36% | 3.34% | Boston,MA |
| 2016 | CVPR | 643 | 83 | 2145 | 29.98% | 3.87% | Las Vegas,NV |
| 2017 | CVPR | 783 | 71 | 2680 | 29.22% | 2.65% | Hawaii,HW |
| 2018 | CVPR | 979 | 70 | 3359 | 29.15% | 2.08% | Salt Lake City,UT |
| 2019 | CVPR | 1294 | 288 | 5160 | 25.08% | 5.58% | Long Beach,CA |
| 2020 | CVPR | 1466 | 335 | 5865 | 25.00% | 5.71% | Seattle,WA |
| 2021 | CVPR | 1660 | 295 | 7015 | 23.66% | 4.21% | Nashville,TN |
| 2022 | CVPR | 2063 | 342 | 8161 | 25.28% | 4.19% | New Orleans, LA |
表1 CVPR論文投稿数および採択率
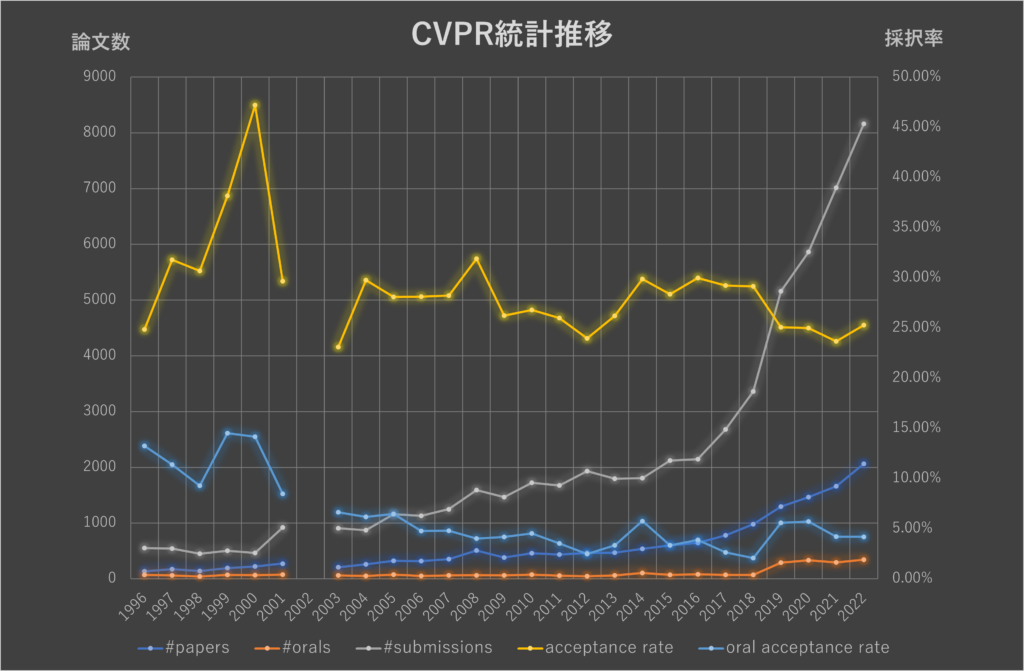
今年は、8,161件の論文が投稿され、2,074件の論文が採択されました。採択率25.41%となります。この内、342件が口頭発表論文として採択されました。これは投稿論文数に対して、たったの4.19%になります。
1996年から比べると採択論文数は15倍強となりました。採択率はここ数年と変わらず横ばいですが、相変わらず難易度は非常に高いことがわかります。なお、投稿論文数は昨年に比べ16%増でした。
余談になりますが、分野成長の観点からは喜ばしい一方、査読システムのことを考えると破綻しているという声も上がっているようです。
■日本人研究者の活躍
単純に論文統計を一行追加しただけでは面白くないので、今回は日本の研究者がどれだけ活躍されているのかということもまとめてみました(図2)。
日本人らしい名前を判定するプログラムを作成し機械的に抜き出しましたので、もし抜けている著者の方がおられたら申し訳ありません。また海外で活躍される日本人研究者もおられますので、所属機関が日本にない場合や、逆に日本の機関に所属しながら活躍される海外の方のお名前を持たれる研究者も含まれていません。そのような集計ではありますが、107人の日本人研究者の発表が確認できました(共著を含む)。
同様の手法で、Computer Vision Foundationに論文が掲載されている2014年から全部やってみた結果が表2です。
今年は昨年と比べると、特に多くの方が活躍されたことがわかります。一方で、論文数と著者数の関係に関する傾向として、平均著者人数も見てみると増加の一途でした。学会が盛況になり難易度が高くなるにつれ、チームワークが重要になってきている様子が見て取れます。
| 開催年 | 論文数 | 著者数 | 平均著者数 | 日本人 著者数 |
日本人 著者比率 |
日本人著者数 を含む論文 |
日本人著者が 絡む論文比率 |
|---|---|---|---|---|---|---|---|
| 2014 | 540 | 1,881 | 3.48 | 45 | 2.39% | 26 | 4.81% |
| 2015 | 602 | 2,207 | 3.67 | 33 | 1.50% | 20 | 3.32% |
| 2016 | 643 | 2,487 | 3.87 | 46 | 1.85% | 22 | 3.42% |
| 2017 | 783 | 3,185 | 4.07 | 61 | 1.92% | 29 | 3.70% |
| 2018 | 979 | 4,214 | 4.30 | 93 | 2.21% | 38 | 3.88% |
| 2019 | 1,294 | 5,863 | 4.53 | 86 | 1.47% | 40 | 3.09% |
| 2020 | 1,466 | 6,970 | 4.75 | 68 | 0.98% | 41 | 2.80% |
| 2021 | 1,660 | 8,087 | 4.87 | 70 | 0.87% | 42 | 2.53% |
| 2022 | 2,074 | 10,874 | 5.24 | 107 | 0.98% | 52 | 2.51% |
表2 CVPR投稿論文全体の著者数に占める日本人比率の推移
CVPR2022での発表件数
| 著者 | 採択数 |
|---|---|
| Mayu Otani |
3
|
| Tatsuya Harada |
3
|
| Yuta Nakashima |
3
|
| Hideki Nakayama |
2
|
| Hirokatsu Kataoka |
2
|
| Jun Saito |
2
|
| Ko Nishino |
2
|
| Koki Nagano |
2
|
| Riku Togashi |
2
|
| Ryosuke Yamada |
2
|
| Shin’ichi Satoh |
2
|
| Shohei Nobuhara |
2
|
| Toshihiko Yamasaki |
2
|
| Yasutaka Furukawa |
2
|
| Yoichi Sato |
2
|
| Yuki MAsano |
2
|
| Yusuke Sugano |
2
|
| Akihiro Sugimoto |
1
|
| Akira Imakura |
1
|
| Atsuhiro Noguchi |
1
|
| Chihiro Tsutake |
1
|
| Daichi Azuma |
1
|
| Daisuke Kihara |
1
|
| Eiichi Matsumoto |
1
|
| Hajime Nagahara |
1
|
| Hidekata Hontani |
1
|
| Hisami Suzuki |
1
|
| Kai Katsumata |
1
|
| Kazuki Okami |
1
|
| Keita Takahashi |
1
|
| Kenichiro Tanaka |
1
|
| Kenta Niwa |
1
|
| Kentaro Wada |
1
|
| Kodai Nakashima |
1
|
| Mariko Isogawa |
1
|
| Masashi Sugiyama |
1
|
| Masatoshi Okutomi |
1
|
| Masayoshi Tomizuka |
1
|
| Michitaka Yoshida |
1
|
| Motoaki Kawanabe |
1
|
| Nakamasa Inoue |
1
|
| Naofumi Akimoto |
1
|
| Naoki Yokoyama |
1
|
| Naoto Yokoya |
1
|
| Naoya Chiba |
1
|
| Norimichi Ukita |
1
|
| Rio Yokota |
1
|
| Ryo Hayamizu |
1
|
| Ryosuke Wakaki |
1
|
| Ryoya Mizuno |
1
|
| Ryuki Yamamoto |
1
|
| Satoshi Ikehata |
1
|
| Shinya Shimizu |
1
|
| Shoichiro Takeda |
1
|
| Shu Ishida |
1
|
| Shuhei Kurita |
1
|
| Shunsuke Saito |
1
|
| Soma Nonaka |
1
|
| Sora Takashima |
1
|
| Soshi Shimada |
1
|
| Taishi Ono |
1
|
| Takahiro Kushida |
1
|
| Takahiro Maeda |
1
|
| Takami Sato |
1
|
| Takashi Isobe |
1
|
| Takayuki Okatani |
1
|
| Taku Komura |
1
|
| Takuhiro Kaneko |
1
|
| Takuma Yagi |
1
|
| Takumi Nishiyasu |
1
|
| Takuya Funatomi |
1
|
| Tatsuya Yokota |
1
|
| Tetsuya Ogata |
1
|
| Tetsuya Sakai |
1
|
| Toshiaki Fujii |
1
|
| Yasuhiro Fujita |
1
|
| Yasuhiro Mukaigawa |
1
|
| Yasuhisa Fujii |
1
|
| Yasuto Nagase |
1
|
| Yoshimitsu Aoki |
1
|
| Yuhi Kondo |
1
|
| Yukiyasu Domae |
1
|
| Yushi Aono |
1
|
| Yusuke Hirota |
1
|
| Yusuke Monno |
1
|
| Yusuke Moriuchi |
1
|
| Yutaro Yamada |
1
|
図2 日本人研究者ごとのCVPR2022での発表件数
■論文出現キーワードの推移
次いで、近年の技術キーワードの推移も見てみることにしました。
タイトルのみを対象として、タスクレベルと手法レベルでキーワードを抜き出し、それぞれの頻度を観測してみました(表3-1・3-2・3-3)。
表に示したのは、全体の論文数に対して0.5%以上出現したキーワードです。
2022年のキーワードランキング堂々の一位は“Transformer”で実に6.32%の論文に出現していました。2022の論文数は2,074本ですので、131本もの論文がTransformerをタイトルに含んでいたことになります。Transformer祭りであったと言っても差し支えないでしょう。議論はありますが、Transformerの出現により、基盤モデル(Foundation model)といったような用語も飛び出し、一つのモデルを構築することで様々なタスクを実現する研究が進んでいるためかもしれません。
その次はObject detectionすなわち物体検出ですが、これは画像認識の普遍的タスクであり、2014年以降毎年トップ5に入るほど高いレベルにあるキーワードです。
| 2014 | 2015 | 2016 | |||
|---|---|---|---|---|---|
| 3D Reconstruction | 1.85% | Sparse | 3.16% | Object Detection | 3.11% |
| Sparse | 1.85% | Object Detection | 2.16% | Sparse | 2.80% |
| Action Recognition | 1.85% | Action Recognition | 1.83% | Unsupervised | 1.87% |
| Unsupervised | 1.67% | Image Classification | 1.33% | Re Identification | 1.71% |
| Object Detection | 1.30% | Unsupervised | 1.16% | Action Recognition | 1.71% |
| 3D | 1.11% | Metric Learning | 1.16% | Semantic Segmentation | 1.56% |
| Wild | 1.11% | Semantic Segmentation | 1.16% | Weakly supervised | 1.40% |
| Weakly supervised | 0.93% | Re Identification | 1.16% | 3D | 1.24% |
| Image Classification | 0.93% | Face Recognition | 1.00% | Attention | 1.09% |
| Object Tracking | 0.93% | Video | 1.00% | Question Answer | 1.09% |
| Object Recognition | 0.74% | Image Retrieval | 0.83% | Zero Shot | 1.09% |
| Semi supervised | 0.74% | Light Field | 0.83% | Image Classification | 1.09% |
| RF | 0.74% | Weakly supervised | 0.83% | Video | 0.93% |
| Pedestrian Detection | 0.74% | Wild | 0.83% | 3D Reconstruction | 0.93% |
| Transfer Learning | 0.74% | 3D Reconstruction | 0.83% | Light Field | 0.93% |
| Visual Tracking | 0.74% | Super Resolution | 0.83% | Captioning | 0.78% |
| Boosting | 0.56% | Domain Adaptation | 0.66% | Neural Network | 0.78% |
| Semantic Segmentation | 0.56% | Multiple Instance Learning | 0.66% | Wild | 0.78% |
| Spatio Temporal | 0.56% | Neural Network | 0.66% | End To End | 0.78% |
| Metric Learning | 0.56% | Depth | 0.66% | Metric Learning | 0.62% |
| Domain Adaptation | 0.56% | Semi supervised | 0.66% | Object Tracking | 0.62% |
| Spectral Clustering | 0.56% | Super Resolution | 0.62% | ||
| Diffusion | 0.56% | Deep Learning | 0.62% | ||
| Dictionary Learning | 0.56% | Face Recognition | 0.62% | ||
表3-1 論文出現キーワード推移(2014-2016年)
| 2017 | 2018 | 2019 | |||
|---|---|---|---|---|---|
| Attention | 2.43% | Adversarial | 6.44% | Adversarial | 5.95% |
| Weakly supervised | 2.43% | Attention | 3.68% | Unsupervised | 4.10% |
| Adversarial | 2.17% | Object Detection | 3.57% | Attention | 3.63% |
| Unsupervised | 2.17% | Re Identification | 3.06% | Object Detection | 3.32% |
| Action Recognition | 2.17% | Unsupervised | 3.06% | Semantic Segmentation | 2.09% |
| Captioning | 2.04% | Weakly supervised | 2.76% | Domain Adaptation | 2.01% |
| Object Detection | 1.92% | Semantic Segmentation | 2.04% | Re Identification | 1.78% |
| Semantic Segmentation | 1.92% | Question Answer | 1.74% | Weakly supervised | 1.70% |
| Wild | 1.66% | End to End | 1.74% | End To End | 1.55% |
| Re Identification | 1.66% | Domain Adaptation | 1.63% | Zero Shot | 1.47% |
| Zero Shot | 1.66% | Sparse | 1.53% | Captioning | 1.47% |
| Spatio Temporal | 1.41% | Zero Shot | 1.43% | Few Shot | 1.39% |
| Question Answer | 1.28% | Point Cloud | 1.23% | Self supervised | 1.39% |
| Deep Learning | 1.28% | Action Recognition | 1.23% | 3D | 1.39% |
| Representation Learning | 1.28% | Captioning | 1.23% | Point Cloud | 1.31% |
| Neural Network | 1.28% | Disentangl | 1.12% | Action Recognition | 1.24% |
| Image Classification | 1.15% | Wild | 1.02% | Instance Segmentation | 1.24% |
| Cross Modal | 1.15% | Reinforcement Learning | 1.02% | Question Answer | 1.24% |
| Video | 1.02% | Super Resolution | 0.92% | Metric Learning | 1.08% |
| Domain Adaptation | 1.02% | Neural Network | 0.92% | Wild | 1.08% |
| End To End | 1.02% | Video | 0.92% | Disentangl | 1.01% |
| Sparse | 1.02% | Self supervised | 0.92% | Representation Learning | 0.93% |
| Reinforcement Learning | 0.89% | Deep Learning | 0.92% | Cross Modal | 0.93% |
| Metric Learning | 0.89% | Style Transfer | 0.82% | Semi supervised | 0.93% |
| Face Recognition | 0.77% | 3D | 0.82% | Neural Network | 0.93% |
| Super Resolution | 0.77% | Face Recognition | 0.72% | Face Recognition | 0.85% |
| 3D | 0.77% | 3D Reconstruction | 0.61% | Spatio Temporal | 0.77% |
| Image Retrieval | 0.64% | Transfer Learning | 0.61% | Transfer Learning | 0.77% |
| One Shot | 0.64% | One Shot | 0.51% | Image Classification | 0.77% |
| Instance Segmentation | 0.64% | Light Field | 0.51% | Sparse | 0.77% |
| Style Transfer | 0.64% | Super Resolution | 0.62% | ||
| 3D Reconstruction | 0.64% | Image Retrieval | 0.54% | ||
| Light Field | 0.64% | Object Tracking | 0.54% | ||
| Subspace Clustering | 0.51% | Image Generation | 0.54% | ||
| Self supervised | 0.51% | ||||
| Fine Tuning | 0.51% | ||||
| Object Recognition | 0.51% | ||||
| Deep Neural Network | 0.51% | ||||
| Autoencoder | 0.51% | ||||
| Object Tracking | 0.51% | ||||
表3-2 論文出現キーワード推移(2017-2019年)
| 2020 | 2021 | 2022 | |||
|---|---|---|---|---|---|
| Adversarial | 4.43% | UnSupervised | 4.70% | Transformer | 6.32% |
| Object Detection | 4.23% | Object Detection | 4.58% | Object Detection | 4.58% |
| Attention | 4.09% | Self Supervised | 3.19% | Self Supervised | 3.71% |
| UnSupervised | 3.55% | Adversarial | 2.89% | Semantic Segmentation | 3.04% |
| Self Supervised | 2.32% | Semantic Segmentation | 2.35% | Attention | 2.84% |
| Domain Adaptation | 2.05% | Attention | 2.23% | Adversarial | 2.84% |
| Semantic Segmentation | 1.91% | Domain Adaptation | 2.23% | UnSupervised | 2.60% |
| Few Shot | 1.77% | Few Shot | 2.23% | Few Shot | 2.36% |
| Semi Supervised | 1.64% | Semi Supervised | 2.11% | Semi Supervised | 2.03% |
| Point Cloud | 1.64% | Point Cloud | 1.99% | Weakly Supervised | 1.98% |
| Re Identification | 1.50% | Representation Learning | 1.75% | Contrastive Learning | 1.98% |
| End to End | 1.50% | Re Identification | 1.63% | Point Cloud | 1.93% |
| Weakly Supervised | 1.43% | Weakly Supervised | 1.63% | Sparse | 1.74% |
| 3D | 1.43% | End to End | 1.45% | Representation Learning | 1.69% |
| Wild | 1.30% | Instance Segmentation | 1.39% | End to End | 1.64% |
| Representation Learning | 1.30% | Cross Modal | 1.27% | Cross Modal | 1.25% |
| Instance Segmentation | 1.23% | Wild | 1.21% | Pre Training | 1.25% |
| Disentangl | 1.02% | Disentangl | 1.21% | Wild | 1.21% |
| Cross Modal | 1.02% | Super Resolution | 1.15% | Domain Adaptation | 1.16% |
| Zero Shot | 0.96% | 3D | 1.08% | 3D | 1.11% |
| Action Recognition | 0.96% | Object Tracking | 1.08% | Instance Segmentation | 1.06% |
| Multi Modal | 0.82% | Sparse | 1.02% | Re Identification | 1.01% |
| Reinforcement Learning | 0.82% | Transformer | 0.90% | Zero Shot | 1.01% |
| Face Recognition | 0.82% | Contrastive Learning | 0.90% | Disentangl | 1.01% |
| Super Resolution | 0.75% | Face Recognition | 0.84% | Multi Modal | 1.01% |
| Spatio Temporal | 0.75% | Pre Training | 0.72% | Knowledge Distillation | 0.96% |
| Sparse | 0.68% | Captioning | 0.66% | Captioning | 0.82% |
| Image Classification | 0.68% | Action Recognition | 0.66% | Incremental Learning | 0.82% |
| Captioning | 0.68% | Spatio Temporal | 0.66% | Image Generation | 0.77% |
| Knowledge Distillation | 0.68% | Zero Shot | 0.60% | Action Recognition | 0.77% |
| Neural Network | 0.68% | Style Transfer | 0.60% | Federated Learning | 0.72% |
| Object Tracking | 0.61% | One Shot | 0.60% | Object Tracking | 0.72% |
| Deep Learning | 0.55% | Incremental Learning | 0.54% | Diffusion | 0.68% |
| Image Generation | 0.55% | Boosting | 0.63% | ||
| 3D Reconstruction | 0.53% | ||||
| Question Answer | 0.53% | ||||
| Continual Learning | 0.53% | ||||
| Super Resolution | 0.53% | ||||
表3-3 論文出現キーワード推移(2020-2022年)
次は、Self-supervisedというキーワードで、これは自己教師付き学習を意味しています。3.71%の論文で出現していましたが、教師付き学習においてアノテーションコストが大量データ学習の障害になっていたのに対して、Contrastive Learning等の方法論が出たことにより、自分で教師信号を与えることで学習を進める方法論が普及していることを示しています。Self-supervised Learningの代表的手法であるContrastive Learningも1.98%の比率で出現していることからこれを足し合わせた、5.69%が自己教師付き学習だったと考えることもできるかもしれません。
関連するところで、Few shot / Semi supervised / Weakly supervisedなども、それぞれ2.36% / 2.03% / 1.98%と高い比率で出現していることから、学習におけるデータ整備コストを少なくする研究は非常に人気のある研究分野です。その他、高い比率で出現しているのは、Adversarial / Attention / Sparseなどです。対象としては、3DやPoint cloudを扱う研究も依然として人気があるようです。CV分野で研究をしている研究者にとっては特に目新しい傾向ではないでしょう。しかし、改めて定量的にどの程度かを観測すると、その盛況感がさらに伝わってくることでしょう。派生して、来年度のホットキーワードを予測するのも面白いかもしれません。
注)キーワード取得のアルゴリズムに一部バグがあり、再度統計を出し修正いたしました。一部順位の入替や比率の変動がございます(2023.6.23更新)。
CVPR論文やトレンドの紹介は、様々な勉強会や研究者ブログでよく紹介されていますので、ここでは統計情報から全体を俯瞰してみました。内容については適宜ご活用ください。
編集:ResearchPort事業部
■Contact
本記事に関する質問や、ご意見・ご要望などがございましたらResearchPortまでお問い合わせください。
https://research-p.com/contactform/
-
2026年4月23日
「ICLR 2026」ResearchPortトップカンファレンス定点観測 vol.21


